スクレイピングした株価情報をjson形式で保存できるようにした
前回保有している株の株価情報をスクレイピングすることができました。
管理・編集しやすいように結果をjson形式のファイルに出力してみました。
サンプルプログラム
import requests import json import time from bs4 import BeautifulSoup def getText(el): """指定した要素内の文字列を返す Args: el (bs4.element.ResultSet): 要素 Returns: str: 要素内の文字列 """ if el is not None: return el.getText() return "" # 処理件数 cnt = 0 # システム日付 sysDate = "" # 銘柄情報リスト stockInfoList = [] # 保有している銘柄コードを取得する自前のAPI # スターサーバー上のMySQLからデータを取得し下記の形式で返します # [{"stock_cd": "1942"}, {"stock_cd": "2730"} res = requests.get("http://xxx.yyy.zzz/codeList") # JSONに変換 data = json.loads(res.text) # 銘柄コード毎に株価情報を取得 for cd in data: # 上限設定 if cnt == 50: break # 株価情報取得 res = requests.get("https://kabutan.jp/stock/?code=" + cd["stock_cd"]) # レスポンスの解析 doc = BeautifulSoup(res.text, "html.parser") # 株価情報の取得 elPrice = doc.select("#kobetsu_left tr") # タイトルの取得 [<th scope="row">終値</th>] elTitle = doc.select("#kobetsu_left th") # 銘柄名の取得 name = doc.select_one(".si_i1_1 h2") # 銘柄名が取得できない場合はスキップ if name is None: continue # 銘柄情報 stockInfo = {} # 銘柄名を設定 銘柄コード+銘柄名で文字列を取得するので銘柄コードをブランクにする stockInfo["stock_cd"] = cd["stock_cd"] stockInfo["stock_na"] = name.getText().replace(cd["stock_cd"], "") # システム日付が未指定の場合は日付を取得 if sysDate == "": # システム日付の取得 [<time datetime="2021-10-08">10月08日</time>] elDate = doc.select("#kobetsu_left h2>time") if elDate is None: break; # システム日付を(yyyymmdd形式)にする sysDate = elDate[0].attrs["datetime"].replace("-", "") # タイトルの解析 if elTitle is not None: # 始値、高値、安値、終値、出来高が存在しない場合はスキップする if len(elTitle) < 5: continue if elTitle[0].getText() != "始値": continue if elTitle[1].getText() != "高値": continue if elTitle[2].getText() != "安値": continue if elTitle[3].getText() != "終値": continue if elTitle[4].getText() != "出来高": continue # 銘柄情報の設定 if elPrice is not None and len(elPrice) >= 5: stockInfo["open_price"] = getText(elPrice[0].select_one("td")).replace(",", "") stockInfo["high_price"] = getText(elPrice[1].select_one("td")).replace(",", "") stockInfo["low_price"] = getText(elPrice[2].select_one("td")).replace(",", "") stockInfo["closing_price"] = getText(elPrice[3].select_one("td")).replace(",", "") stockInfo["vol"] = getText(elPrice[4].select_one("td")).replace("\u00a0\u682a", "").replace(",", "") stockInfoList.append(stockInfo) # カウントアップ cnt+=1 # 1秒停止 time.sleep(1) if sysDate != "": dt = {} dt["dt"] = sysDate dt["stock_info"] = stockInfoList filePath = "C:/data/" fileNa = sysDate + "_stock_price.json" with open(filePath + fileNa, mode='a') as fo: fo.write(json.dumps(dt))
出力したjsonファイル
{ "dt": "20211012", "stock_info": [ { "stock_cd": "1942", "stock_na": "\u95a2\u96fb\u5de5", "open_price": "918", "high_price": "922", "low_price": "914", "closing_price": "914", "vol": "184300" }, { "stock_cd": "2730", "stock_na": "\u30a8\u30c7\u30a3\u30aa\u30f3", "open_price": "1097", "high_price": "1103", "low_price": "1081", "closing_price": "1084", "vol": "473000" } ] }
日付、銘柄コード、銘柄名、始値、高値、安値、終値、出来高を保存するようにしました。
取得した株価情報はこの後スターサーバー上のMySQLに登録する予定です。
本当は全部サーバー上でやりたいのですが、BeautifulSoupのインストールが難しそうなのでローカルで解析するようにしました。
pythonで株価をスクレイピングする
前回Webページのスクレイピングまでできたので今回は株価のスクレイピングを試します。
株探のページ情報
URL
ソース(一部)
<div id="kobetsu_left"> <dl> <dt>前日終値</dt> <dd class="floatr">3,340.0 (<time datetime="2021-10-06">10/06</time>)</dd> </dl> <h2><time datetime="2021-10-07">10月07日</time></h2> <table> <tbody> <tr> <th scope="row">始値</th> <td>3,200.0</td> <td class="mark"> </td> <td>(<time datetime="2021-10-07T09:03+09:00">09:03</time>)</td> </tr> <tr> <th scope="row">高値</th> <td>3,245.0</td> <td class="mark"> </td> <td>(<time datetime="2021-10-07T14:52+09:00">14:52</time>)</td> </tr> <tr> <th scope="row">安値</th> <td>3,157.0</td> <td class="mark"> </td> <td>(<time datetime="2021-10-07T09:06+09:00">09:06</time>)</td> </tr> <tr> <th scope="row">終値</th> <td>3,221.0</td> <td class="mark"> </td> <td>(<time datetime="2021-10-07T15:00+09:00">15:00</time>)</td> </tr> </tbody> </table> ・ ・ ・ </div>
株探の解析
サンプルプログラム
import requests from bs4 import BeautifulSoup res = requests.get("https://kabutan.jp/stock/?code=4502") doc = BeautifulSoup(res.text, "html.parser") el = doc.select("#kobetsu_left tr") if el is not None: for row in el: print(row.select("td"))
selectメソッドにCSSセレクタ("#kobetsu_left tr")を指定して要素を取得します。
取得した要素の中からさらにselectメソッドにCSSセレクタ("td")を指定して取得した要素を出力してみます。
実行結果
[<td>3,200.0</td>, <td class="mark"> </td>, <td>(<time datetime="2021-10-07T09:03+09:00">09:03</time>)</td>] [<td>3,245.0</td>, <td class="mark"> </td>, <td>(<time datetime="2021-10-07T14:52+09:00">14:52</time>)</td>] [<td>3,157.0</td>, <td class="mark"> </td>, <td>(<time datetime="2021-10-07T09:06+09:00">09:06</time>)</td>] [<td>3,221.0</td>, <td class="mark"> </td>, <td>(<time datetime="2021-10-07T15:00+09:00">15:00</time>)</td>] ・ ・ ・ ・
株価部分を含んだ要素が取得できてますね。
この結果からさらに株価部分を取得できれば目的は達成できます。
サンプルプログラム
import requests from bs4 import BeautifulSoup res = requests.get("https://kabutan.jp/stock/?code=4502") doc = BeautifulSoup(res.text, "html.parser") el = doc.select("#kobetsu_left tr") if el is not None: print("始値" + el[0].select("td")[0].getText()) print("高値" + el[1].select("td")[0].getText()) print("安値" + el[2].select("td")[0].getText()) print("終値" + el[3].select("td")[0].getText())
保有中の株の株価を自動集計したいのでpythonでスクレイピングする方法を調査
保有中の株の株価を自動で取得してデータベース化したいのでpythonでスクレイピングする方法を調査しました。
requestsモジュール
最低限必要なのはrequestsモジュール
pipコマンドを使ってインストールします。
pip3 install requests
サンプルプログラム
scrape_html.py
import requests import json res = requests.get("http://sample.kansai-fan.com/py/pymysql.py") print(res.text)
requestsモジュールのgetメソッドで指定したURLのレスポンスを取得
レスポンスのtextプロパティを出力すればhtmlの内容が出力されます。
実行結果
<html><meta charset='utf-8'><body> <h1>PyMySQLサンプル</h1> 件数2 </body></html>
BeautifulSoupモジュール
次にやりたいのはhtmlから特定のデータを抽出すること。
これはBeautifulSoupモジュールを使えば簡単に実装できます。
こちらもpipコマンドを使ってインストールします。
pip3 install beautifulsoup4
サンプルプログラム
scrape_html.py
import requests import json from bs4 import BeautifulSoup res = requests.get("http://sample.kansai-fan.com/py/pymysql.py") doc = BeautifulSoup(res.text, "html.parser") el = doc.find("h1") if el is not None: print(el.get_text())
コンストラクタで取得したhtmlとパーサーを指定すれば解析は完了。
後はfindメソッドを使って要素を取得、get_text()メソッドで内容を表示させます。
実行結果
PyMySQLサンプル
<h1>の内容が出力されました。
findメソッドにタグを指定すると最初の要素のみ取得。
複数の要素を取得したいときはfind_allメソッドを使う必要があります。
これでスクレイピングの準備は完了。
次回は株価取得に挑戦する予定です。
スターサーバーでpythonからMySQLに接続できた!
前回はpythonで使えるMySQLライブラリを調べてみました。
結論から言うとmysql-connector-pythonとPyMySQLを使ってMySQLに接続してデータを取得することができました。
ライブラリのダウンロードと設置
mysql-connector-python
下記からmysql-connector-python-8.0.26.tar.gz をダウンロードする。
解凍してmysqlディレクトリをサーバーにアップロードする。

アップロード後

動作確認用のテーブル
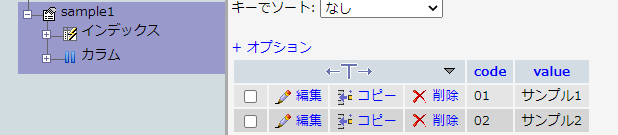
サンプルプログラム(mysql-connector-python)
mysqlconnector.py
#!/usr/bin/python3.6 import mysql.connector as mydb import sys, io sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding = 'utf-8') connection = mydb.connect(host='aaa.bbb.ccc', port='3306', user='dbuser', password='dbpassword', database='db_sample', charset='utf8' ) cursor = connection.cursor() cursor.execute("select count(*) as cnt from sample1") cnt = 0 row = cursor.fetchone() if row is not None: cnt = row[0] cursor.close() connection.close print("Content-Type: text/html; charset=utf-8\n") print("<html><meta charset='utf-8'><body>") print("<h1>mysql-connector-pythonサンプル</h1>") print("件数" + str(cnt)) print("</body></html>")
サンプルプログラム(PyMySQL)
pymysql.py
#!/usr/bin/python3.6 import pymysql import pymysql.cursors import sys, io sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding = 'utf-8') # コネクションの作成 connection = pymysql.connect(host='aaa.bbb.ccc', user='dbuser', port=3306, password='dbpassword', db='db_sample', charset='utf8', cursorclass=pymysql.cursors.DictCursor) cursor = connection.cursor() cursor.execute("select count(*) as cnt from sample1") cnt = 0 row = cursor.fetchone() if row is not None: cnt = row["cnt"] print("Content-Type: text/html; charset=utf-8\n") print("<html><meta charset='utf-8'><body>") print("<h1>PyMySQLサンプル</h1>") print("件数" + str(cnt)) print("</body></html>")
コネクション関連の設定はmysql-connector-pythonとほぼ同じ。
ポートの指定が数値型なのとcursorclassにpymysql.cursors.DictCursorを指定することにより結果を辞書型で返してくれます。
実行結果


件数がちゃんと出力されました。
これでスターサーバーでpythonとMySQLを使ってWebアプリを作る環境が整いました。